
- True Positive (TP): The values which belonged to class 1 and were predicted 1.
- False Positive (FP): The values which belonged to class 0 and were predicted 1.
- False Negative (FN): The values which belonged to class 1 and were predicted 0.
- True Negative (TN): The values which belonged to class 0 and were predicted 0.
Clearly, we want True Positives and True Negatives to be predicted. However, no machine learning algorithm is completely perfect, and we end up with False Positive and False-negative due to misclassifications. This confusion in classifying the data can be easily shown by a matrix, called the Confusion Matrix:
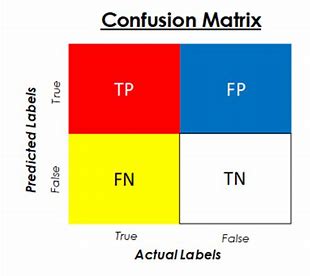
From a confusion matrix, we can obtain different measures like Accuracy, Precision, Recall, and F1 scores.
Accuracy
Accuracy represents the number of correctly classified data instances (TN+TP) over the total number of data instances (TN+TP+FN+FP) which is as follows:
Accuracy is a very good measure if negative and positive classes have the same number of data instances, which means that the data is balanced. In reality, we can hardly find balanced data for classification tasks.
Recall
Recall can be used as a measure, where Overlooked Cases (False Negatives) are more costly, and the focus is on finding the positive cases. The recall is calculated as follows:
For example, in a loan classification model, if predict a non-delinquent customer as a delinquent customer, bank would lose an opportunity of providing loan to a potential customer. We need to reduce False Negatives, as such recall should be maximized (the greater the recall, higher the chances of minimizing the false negative).
Precision
Precision is a good evaluation metric to use when the cost of a false positive is very high and the cost of a false negative is low. Precision is calculated as follows:
F1-Score
F1 score is the combination of Precision and Recall. If we want our model to be correct and not miss any correct predictions, then we want to maximize both Precision and Recall scores. F1 score is defined as follows:
