
A model is overfit if it works better on training data than it does on other data.
Overfitting can be avoided in several ways. The simplest way is to have a dataset that’s a better representation of what is seen in the real world.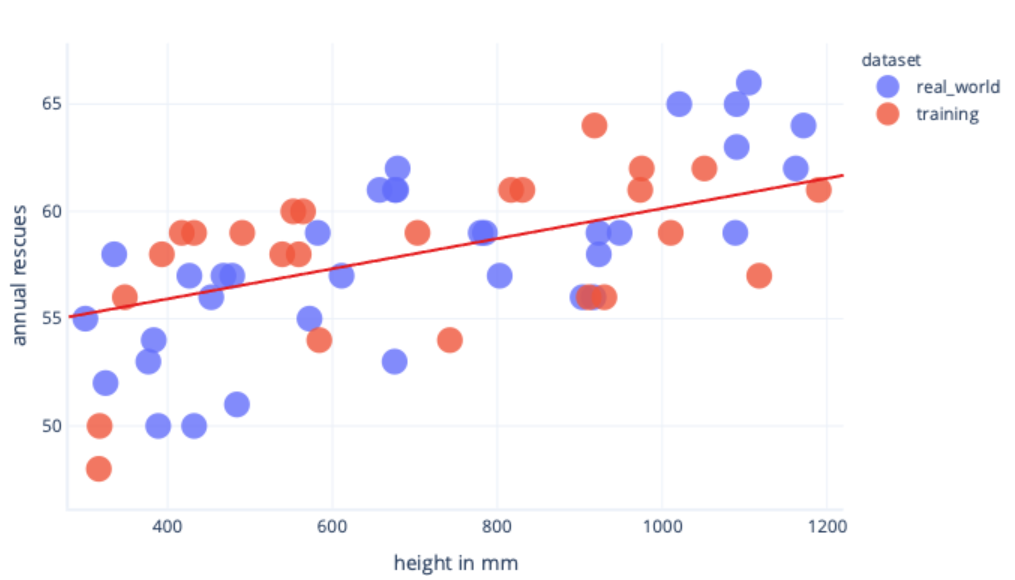
A complimentary way we can avoid overfitting is to stop training after the model has learned general rules, but before the model is overfit. This requires detecting when we’re beginning to overfit our model, though. We can do this using a test dataset.
First, if test performance stops improving during training, we can stop; there’s no point in continuing. If we do continue, we can end up encouraging the model to learn details about the training dataset that aren’t in the test dataset, which is overfitting.
Secondly, we can use a test dataset after training. This gives us an indication of how well the final model will work when it sees “real-world” data it hasn’t seen before.
