
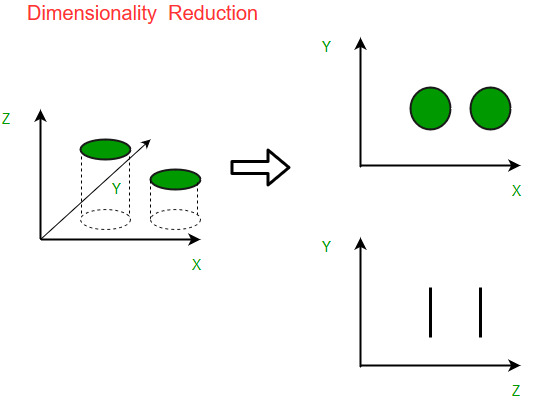
There are various techniques for dimensionality reduction, and they fall into the category of unsupervised learning because they operate on the input data without relying on labeled output information. The primary objective is to simplify the data representation and remove irrelevant or redundant features, making it more manageable and often improving the performance of machine learning models.
Common unsupervised dimensionality reduction techniques include:
- Principal Component Analysis (PCA): A linear technique that identifies the principal components (linear combinations of features) that capture the most variance in the data.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): A non-linear technique that focuses on preserving pairwise similarities between data points in a lower-dimensional space.
- Autoencoders: Neural network-based models that learn an efficient representation of the input data by encoding it into a lower-dimensional space and then reconstructing the original data.
These techniques are applied to datasets without relying on labeled target values, making them unsupervised in nature. Dimensionality reduction is commonly used for tasks such as data visualization, noise reduction, and improving the efficiency of machine learning models, especially when dealing with high-dimensional data.
Important points:
- Dimensionality reduction is the process of reducing the number of features in a dataset while retaining as much information as possible. This can be done to reduce the complexity of a model, improve the performance of a learning algorithm, or make it easier to visualize the data.
- Techniques for dimensionality reduction include: principal component analysis (PCA), singular value decomposition (SVD), and linear discriminant analysis (LDA).
- Each technique projects the data onto a lower-dimensional space while preserving important information.
- Dimensionality reduction is performed during pre-processing stage before building a model to improve the performance
- It is important to note that dimensionality reduction can also discard useful information, so care must be taken when applying these techniques.
Go back to Unsupervised Learning