
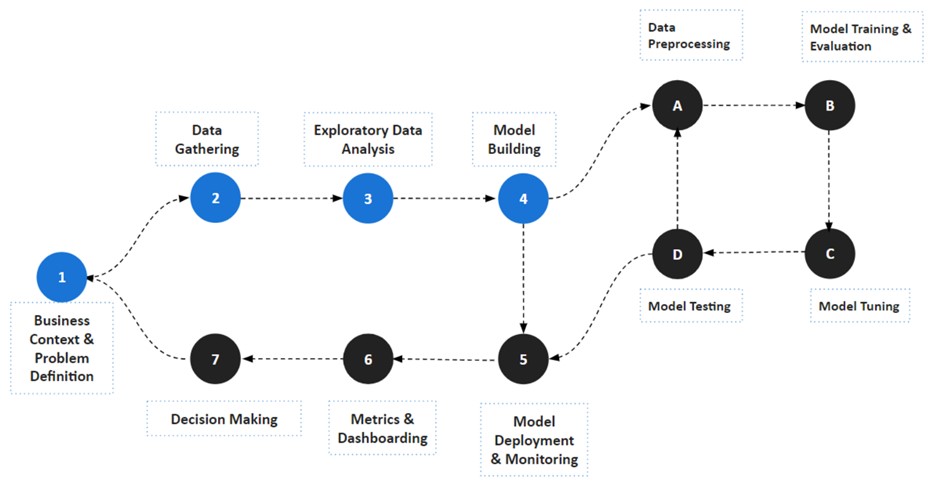
The workflow for implementing Artificial Intelligence and Machine Learning solutions typically involves several stages. Collaborative efforts among data scientists, domain experts, and stakeholders are crucial throughout the process. The specific details of the workflow can vary based on the complexity of the problem, the type of algorithm used, and the specific requirements of the project.
Below is a generalized workflow that outlines the major stages in the development of AI and ML solutions:
Models are the core component of machine learning, and ultimately what we are trying to build.
Problem Definition
Data Collection
Exploratory Data Analysis
Data Exploration: Use visualizations to explore the distribution of individual features, relationships between variables, and potential patterns within the data. Histograms, scatter plots, and pair plots are commonly used for this purpose.
Data Preprocessing: Clean and preprocess the data to handle missing values, outliers, and ensure consistency. This step is crucial for the effectiveness of the model.
Feature Engineering: Select and create features (input variables) that are most relevant to the problem. Feature engineering helps improve the model’s performance.
Model Selection
Model Training
Model Evaluation
Model Tuning
Deployment
Monitoring and Maintenance
Feedback Loop
It’s important to note that the specific details of the workflow may vary depending on the nature of the AI and ML solution, the industry, and the complexity of the problem being addressed. Additionally, ethical considerations and data privacy should be integrated into each stage of the workflow.