
AdaBoost (Adaptive Boosting) is a popular ensemble learning algorithm used for classification and regression tasks.
It works by combining multiple weak learners (typically decision trees, often referred to as “stumps”) to create a strong learner. Here’s how it generally works:
- Initialization: Each data point is initially assigned an equal weight.
- Training Weak Learners: AdaBoost sequentially trains a series of weak learners, where each subsequent learner focuses more on the examples that the previous ones misclassified. The first weak learner is trained on the original dataset.
- Weighting: After each iteration, the weights of incorrectly classified data points are increased. This means that the next weak learner will pay more attention to those misclassified points.
- Combining Weak Learners: Each weak learner is given a weight based on its accuracy, and their outputs are combined through a weighted sum to form the final strong learner.
- Final Model: The final model is a weighted sum of the weak learners’ predictions, where the weights are determined during the training process.
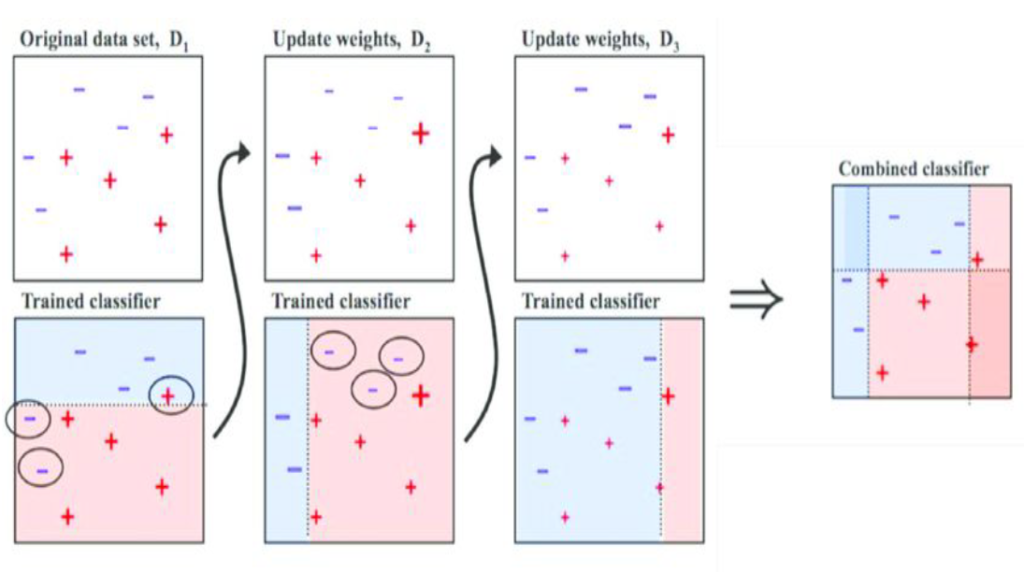
AdaBoost is effective because it focuses on improving the classification of difficult examples by giving them higher weights during subsequent iterations. This makes it particularly useful when dealing with complex datasets where simple models may struggle to generalize well.
The boosting algorithm builds models sequentially while the bagging algorithm builds models parallelly.
The samples which are incorrectly predicted by the previous weak learner will be given more weightage when they are used for training the subsequent weak learner.
Here’s a Python example demonstrating how to implement AdaBoost using the popular scikit-learn library:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Generate a synthetic dataset for demonstration
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize a base weak learner (Decision Tree with max depth 1)
base_learner = DecisionTreeClassifier(max_depth=1)
# Initialize the AdaBoost classifier
adaboost_clf = AdaBoostClassifier(base_estimator=base_learner, n_estimators=50, random_state=42)
# Train the AdaBoost classifier
adaboost_clf.fit(X_train, y_train)
# Make predictions on the test set
y_pred = adaboost_clf.predict(X_test)
# Evaluate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
This example uses scikit-learn to create a synthetic dataset, split it into training and testing sets, initialize a Decision Tree as the base weak learner (with a maximum depth of 1), and then initialize and train an AdaBoost classifier with 50 weak learners. Finally, it makes predictions on the test set and evaluates the accuracy of the model.
